This week I've digested multiple papers and they are all not necessarily related but I believe it was still required to gain understanding on how to move forward with the project. Here is a day-wise summary of my progress throughout the week:
Monday:
Studied the Fast Nonparametric Conditional Density Estimation paper. The paper details a method to calculate the ideal bandwidths for the Kernel methods(sigma in case of the Gaussian Kernel). They have made use of Dual-tree recursion to reduce the time complexity of the operation to O(n2). The previous best method, calculating integrated squared errors(ISE) was of O(n3) so this method saves a lot of time without compromising accuracy when dealing with large datasets. However, calculating bandwidths is not a priority right now, so after discussion with Roger sir, I have shifted my attention towards extending our kernel technique to condition on multiple variables.
Tuesday:
Revisited the Nonparametric Conditional Density Estimation paper to clarify some doubts. The paper states “...two-step estimator may achieve an improved convergence rate relative to the conventional direct estimator” however it was unclear if it implied the improved convergence with respect to time or data points. SInce we had already established the 2-step method is slower, I compared the average error vs data points, here is the result:
The 2-Step method does indeed converge to the ideal curve faster than the 1-step method but it's not significant enough to warrant the longer calculation times(shown below):
Datapoints | Time(in seconds) |
1 Step estimator | 2 Step estimator |
1000 | 1.7074 | 2.050 |
2500 | 4.2389 | 7.9271 |
5000 | 7.8910 | 19.5437 |
7500 | 11.3831 | 41.9696 |
10000 | 15.2220 | 70.7319 |
Wednesday:
Studied the
Smoothed kernel conditional density estimation paper shared by Roger sir in hopes that it would provide some leads into conditioning on multiple variables. However the paper goes into how to deal with calculating the f(y|x) function when there exists
multiple values of y for the same value of x in the dataset. For example, (2,4) , (2,7) , (2,5) are (x,y) pairs belonging to the same dataset.
This type of problem is encountered in BMI vs age charts for instance, as people belonging to the same age can have different BMI scores. The solution proposed in the paper is to substitute the weighted average of all K(y,Y[i]) (where Y[i] is the list of different y values for the same x) in the regular 1-Step estimator formula in place of the usual K(y,Y) in the numerator. While this could be useful in niche datasets, it does not provide any leads to conditioning on multiple variables as the premise is fundamentally different.
Thursday:
Explored the
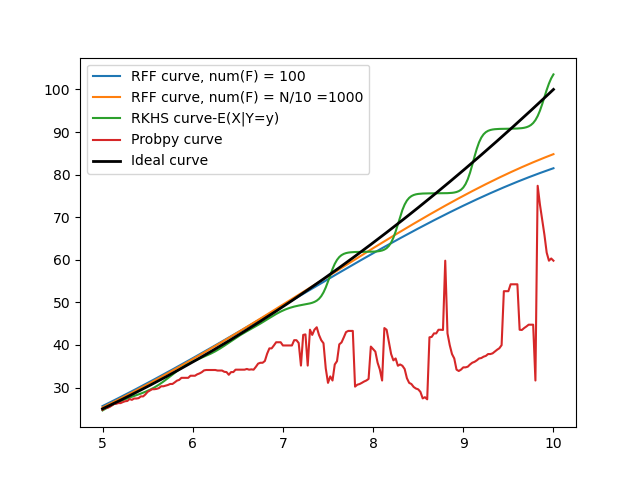
Random Features for Large-Scale Kernel Machines paper and the corresponding lecture Talk on "
Random kitchen Sinks" where the author explains a method involving random features to speedup kernel calculations. He proposes to map the input data to a randomized low-dimensional feature space and then apply existing fast linear methods (this will be faster compared to our Kernel techniques that go through the entire dataset for each iteration). The randomized features are designed so that the inner products of the transformed data are approximately equal to those in the feature space of a user-specified shift-invariant kernel.
The author explores two sets of random features, provides convergence bounds on their ability to approximate various radial basis kernels, and shows that in large-scale classification and regression tasks linear machine learning algorithms that use these features outperform state-of-the-art large-scale kernel machines.
Friday:
Discussed with Mayank on how to implement the random features method as he had found some R code that does the same and converted it to python. Also referred to the
Random Fourier Features article to understand how exactly Random Features are used in lieu of Kernel Methods as the original paper contained some complicated math.
Upcoming Week Plans:
Implement the Random Feature method and compare it with our existing kernel methods. Research on how to implement conditional probability on multiple variables.


Comments
Post a Comment