Week 7: Getting started with Filter-RKHS
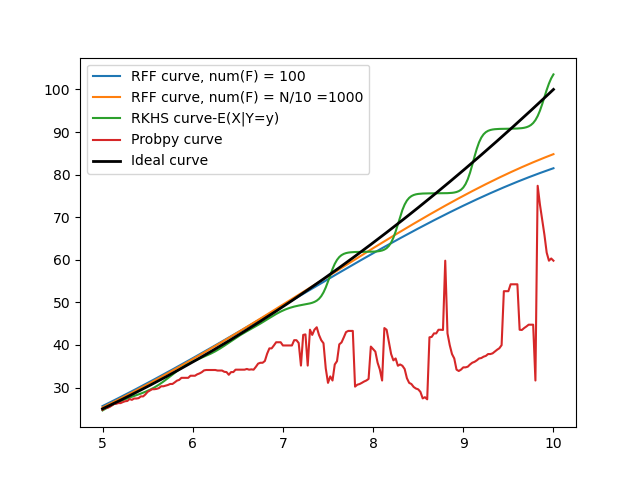
This week I revisited the RKHS method to confirm that we are on the right track and got started with implementation of the Filtered-RKHS method. Here is a day-wise summary of my progress throughout the week: Monday & Tuesday: Analysed the RFF code to reduce the time taken for calculations. Implemented an RFF calculation method according to the formula: As described in this article where z(x) T z(y) is the equivalent calculation to k(x,y), the basic kernel function. The kernel techniques we employ use an iterative approach instead being performed through matrix operations. As a result of this, it involves calling the k(x,y) function repeatedly over the length of the dataset to produce results. I could not figure out how replacing the RFF calculations instead of RKHS kernel calculations would speed up the calculations. If anything, it is going to be slower because while the k(x,y) function is a straightforward calculation, the RFF method iterates over R random selected ...

