Week 4: Two Step Estimator

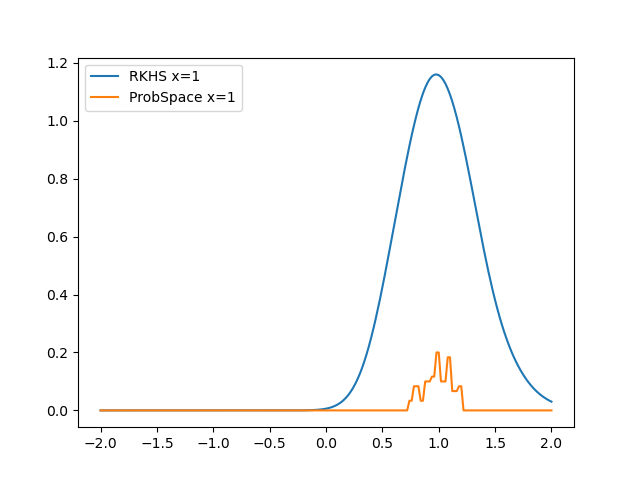
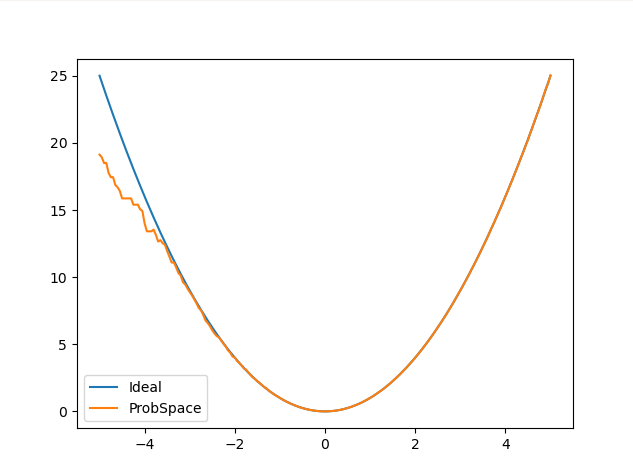
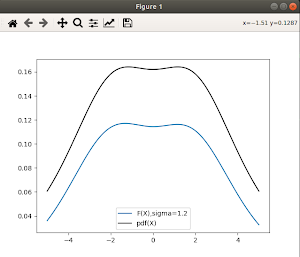
This week I implemented the 2-Step estimator from this paper ( Nonparametric Conditional Density Estimation) and compared the results with the 1-Step estimator I had implemented in the previous week from the same paper. Also found out a shortcut method to calculate E(Y|X=x) that is not only more accurate than the existing ProbSpace method, but also much faster. Monday: Studied the 2-step Estimator method from the Nonparametric Conditional Density Estimation paper. Had a discussion with Roger sir regarding future goals and objectives. Apart from optimizing the RKHS method further using the Dual Tree method , we have to integrate the RKHS method into the ProbSpace module. Implemented an optimization metric during the RKHS calculation phase that allows us to skip calculations that have very little effect towards our answer. This allowed us to reduce the time for calculations significantly: “ Or Optimization ”, bound = 3*sig...