Week 11: Improving UPROB
This week I improved the UPROB module, implementing a UPROB(K-100) functionality, internalizing the filtration operation to automatically choose optimal minimum and maximum points. I also overcame last weeks challenge of caching and managed to implement a working cache functionality for CondP().
Monday :
Discussed functionalities of UPROB with Roger sir and got some suggestions and feedback. Some of the things I will be implementing to improve UPROB are:
Calculate minPoints and maxPoints for filtering operations internally and abstract it from the user.
Implement UPROB(K=100)
Caching the RKHS depending on the filter values rather than filtered variables to avoid re-initializing it. This solves the issue I had last week with caching.
Tuesday and Wednesday:
Implemented the caching functionality. This will especially be helpful in condP() calculation to perform operations where we are only altering the value of expected variable with constant conditionals. For ex:
The following operations can be performed with a single rkhs
P(A = 1 | B = 2, C = 3)
P(A = 3 | B = 2, C = 3)
P(A = 5 | B = 2, C = 3)
Implemented a variant of UPROB(K=100) not involving the usage of an RKHS. To explain the working :
In a simple example of 3 dimensions, A, B and C, When we are trying to find out say, P(A|B= 1, C= 2), after filtering the dataset, we are left with some N data-points of the form:
(a1, 1, 2) ; (a2, 1 , 2) ; (a3, 1 , 2) ......... (an, 1 , 2). for some values of a1,a2,a3...,an
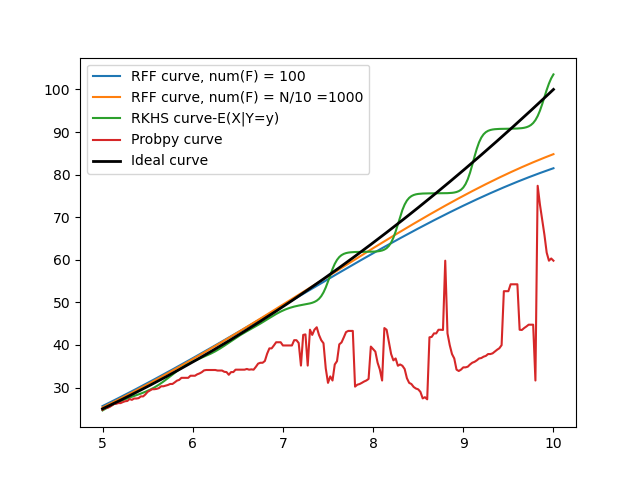
In such a dataset I deduced that the average of all these a1,a2,a3....,an values should provide us with the expected value of A. I implemented this and sure enough, the r2 values of this method is very similar to ProbSpace.
Here are some results for dims = 2,3,4,5,6; datSize = 1000; K = 100
dims, datSize, tries, K = 2 1000 10 100
Average R2: JP, UP, PS = 0.95948351161 0.9917388944263 0.9618719349801685
dims, datSize, tries, K = 3 1000 10 100
Average R2: JP, UP, PS = 0.9470697228 0.759582385234 0.8081795917910626
dims, datSize, tries, K = 4 1000 10 100
Average R2: JP, UP, PS = 0.9078011903 0.687716501589 0.6617432174774956
dims, datSize, tries, K = 5 1000 10 100
Average R2: JP, UP, PS = 0.8003123156 0.404339122151 0.3788512381207686
dims, datSize, tries, K = 6 1000 10 100
Average R2: JP, UP, PS = 0.528478955 0.037851936471 -0.0110369733116401
Thursday and Friday:
Implemented UPROB(K=100) but this time, using a single-dimensional RKHS.
P(A = 1| B = 2, C = 3)
Similar to the previous method, I filter first on all of the conditional variables (B,C), I then pass the remaining data points (only the values of A from the results after filtration) into an RKHS to calculate the expected value of the A. I run this query for different values of A and the mean of these results will give me the E(A | B = 2, C = 3).
I was pleasantly surprised that the results of this method are highly accurate:
dims, datSize, tries = 2 1000 1
Average R2: JP, UP, PS = 0.842644618 0.9828869871 0.9696438228341947
dims, datSize, tries = 3 1000 1
Average R2: JP, UP, PS = 0.717250601 0.73071595754 0.7154192883214503
dims, datSize, tries = 4 1000 1
Average R2: JP, UP, PS = 0.664790677 0.72162423052 0.6011758633380084
Next I implemented minPoints and maxPoints calculations:
self.minPoints = ceil(self.N**((dims-filter_len)/dims))*self.rangeFactor
self.maxPoints = ceil(self.N**((dims-filter_len)/dims))/self.rangeFactor
Here the goal was to find the optimal rangeFactor value so that the filtering operations would be optimal.
While I was running tests, I detected a fatal error in the filtering operation, ProbSpace.filter() we have been using so far. The way ProbSpace is configured, if Probspace cannot get at least minPoints number of data-points within a certain range of the conditional value, it increases the range and checks again. It tries this for 8 iterations. If by chance it was unable to find minPoints number of datapoints even then, it returns 0 data-points (this generally only happens if the dataset we are using is of small size (N ~= 1000).
This is a problem because we cannot initialize our RKHS with 0 data points and this error crashes the testing program. After discussion with Roger sir, I will be implementing a failsafe in place such that if UPROB(K=100) returns 0 data points, I try again with UPROB(K=80) or whatever value of K corresponding to all but 1 conditional variable being filtered. In other words, we progressively reduce the number of variables to be filtered until we obtain the required minimum amount of data points.
I have implemented this new K-decrement filtering but the variables need some fine tuning to work properly as in its current state, the filtering algorithm always drops to calculating UPROB(K=0) which is just JPROB, reducing accuracy.
Next week plan:
Perfect the K decrement algorithm such that it only reduces K when the obtained number of data points from filtration is 0.

Comments
Post a Comment