Week 3: Conditional Probability Implementation
Implemented Conditional Probability calculations using RKHS and compared it to the existing ProbSpace method. On the bright side, the RKHS method is more accurate as we go farther from the mean, but it is also very slow in comparision. Here is a day-wise summary of my progress throughout the week:
Monday:
Studied paper on Nonparametric Conditional Density Estimation. This paper is much easier to digest compared to the previous one we were working on. Clarified some doubts about the terminology and had a discussion about the formulae with Roger sir during the weekly meeting.
f (y | x) = f(y, x)/ f(x) = Σ Kh2(x − Xi) * Kh1(y − Yi) / Σ Kh2 (x − Xi)
This is the main formula we will be working with to calculate E(y|x) and later extend it to calculate E(Y|X)
Tuesday:
Implemented the equation and scaling issues aside, the results show promise to be better than the existing method in the Prob.py script. Generated dataset with Y = X2.
Shown here is the results for P(y=1|x=1) for the RKHS method vs ProbSpace method.
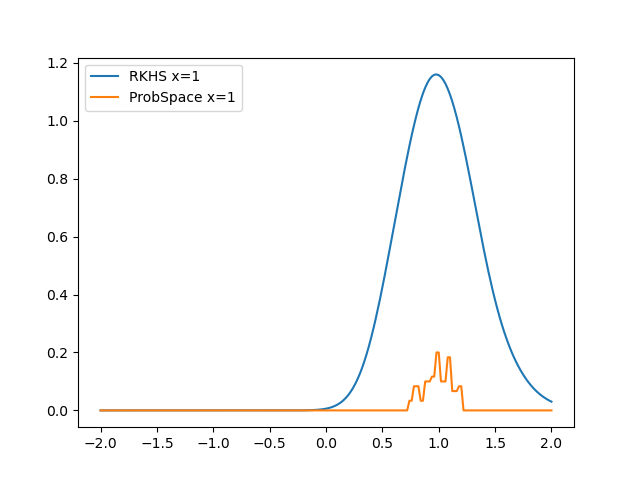
Wednesday:
Implemented E(Y|X) and it was clear that the RKHS method was taking far too long to produce results. For example just calculating for a range of X(-2,2) took 10 minutes. While the ProbSpace method took under 10 seconds. The reason being that, for every value of x∈(-2,2) xi , we are calculating the weighted average of E(y = yi | x = xi ) where y ranges from (-30,30) with a step size of 0.1. The results show that even though the RKHS method is accurate, it is still slightly worse than the ProbSpace method.
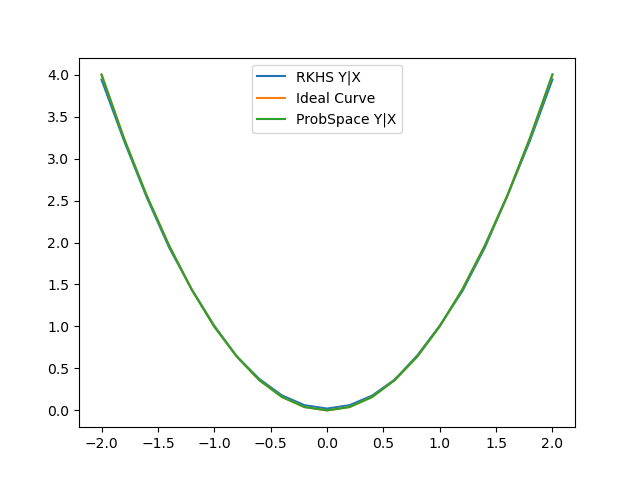
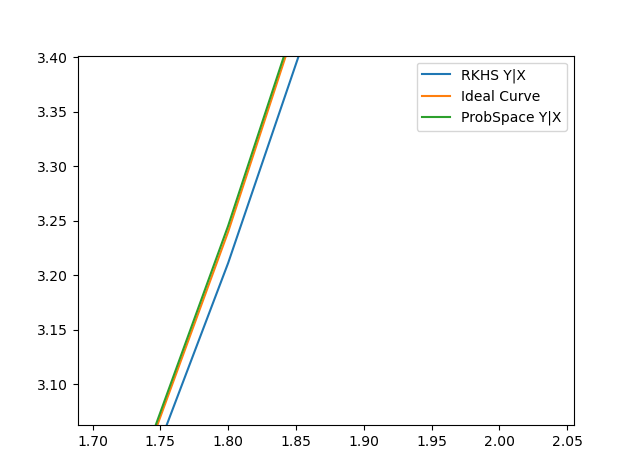
Thursday:
Fine-tuned the algorithm to run faster. This mainly involved the optimization of Y range and step size. It is a waste of time to iterate Y over negative values because for example, P(y= -5| x = 3) is negligibly small and just impractical given that we know Y = X2 . And the real problem with ProbSpace method can only be seen when we deviate farther from the mean of the distribution, so I rescaled X to (-10,10) and Y to (0,100) with step size of 0.5 and 1 , as the error values between step sizes of 0.1 and 0.5 are not different enough justify the slow calculation. The Results are very good, as we move away from the mean ProbSpace curve just falls apart while the RKHS curve is still comparable to the ideal one.
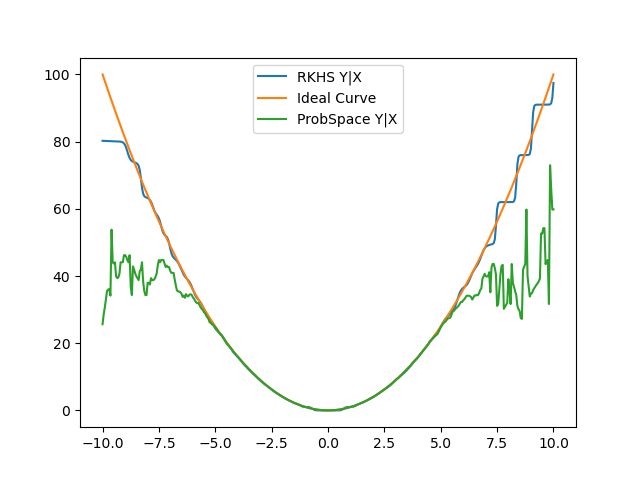
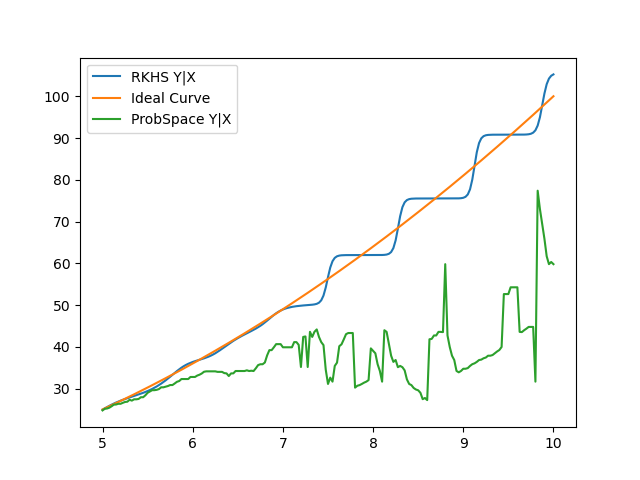
Friday:
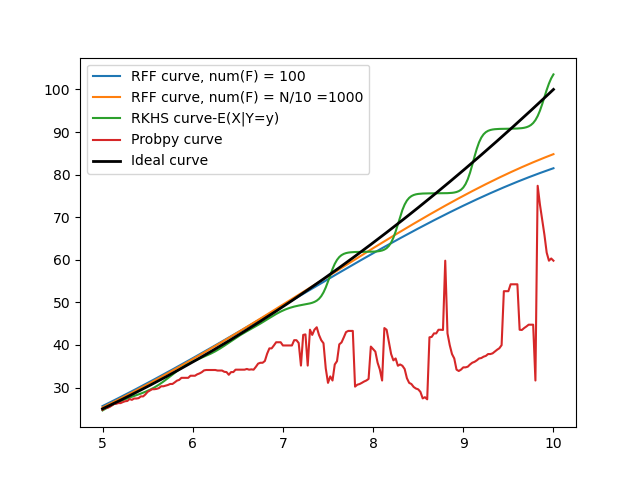
Tested accuracy vs different values of sigma. Here are some of the results:
Prob.py Average Error: 15.786311330384414 Max error: 46.721149191232456
Sigma-0.1 Average Error: 1.7544741739568277 Max error: 6.819402462723623
Sigma-0.2 Average Error: 1.457341151925867 Max error: 5.0603293918499475
Sigma-0.5 Average Error: 3.6074782584714513 Max error: 6.64324125835352
Measured time taken(in seconds) in comparison to Prob.py w.r.t different step sizes
Prob.py Time: 8.134860754013062
Average Error: 15.786311330384414 Max error: 46.721149191232456
RKHS Step Size = 0.5 , Time: 719.6718242168427
Average Error: 1.3966743172847627 Max error: 5.431449933619589
RKHS Step Size = 1 , Time: 731.5105772018433
Average Error: 1.457341151925867 Max error: 5.0603293918499475
RKHS Step Size = 2 , Time: 365.7068731784820
Average Error: 1.4374872842382438 Max error: 5.000025328500016
RKHS Step Size = 5 , Time: 122.54302167892456
Average Error: 2.8136193250540837 Max error: 11.76926483287589
RKHS Step Size = 10 , Time: 61.639594078063965
Average Error: 8.114348240870235 Max error: 30.99998027979695
Upcoming week plans:
Explore the Dual-Tree approximation from the Fast Nonparametric Conditional Density Estimation paper. The aim is to cut the time taken for calculation while maintaining accuracy.

Comments
Post a Comment