Week 6: Implementation of RFF
This week I implemented the RFF method and compared results with the RKHS and ProbSpace methods. Here is a day-wise summary of my progress throughout the week:
Monday:
Discussed some possible methods of multiple variable conditioning with Roger sir during our weekly meets. It is surprisingly hard to find papers on the topic and after many attempts to find one that could help what we are trying to achieve and failing, it seems like we will have to implement this feature by ourselves. We can take inspiration from how ProbSpace does it and extend it to kernel methods if possible, else we can try a hybrid of the two.
Roger sir was also looking into using RKHS to rebuild a probability distribution curve from the filtered data points(the Probspace method of doing conditional probabilities is essentially filtering the data repeatedly on each conditional variable value). This could help us solve the dwindling data points problem that occurs upon repeated filtering. I studied some conditional probability theory to see if there was some obvious method we were missing but conditional probability calculations are tightly tied to joint probability distributions so, no luck there.
Tuesday:
Upon Roger sir’s suggestion, I have shifted the objectives of my project as the quest for implementing multiple conditioning is at a dead end as of now. I will be focussing on 3 separate things going forward involving modification of Probspace methods, integration of RKHS into Probspace methods and implementing Random Fourier Features and testing the accuracy/results of all of these. Started working on implementation of RFFs today based on this blog.
Wednesday:
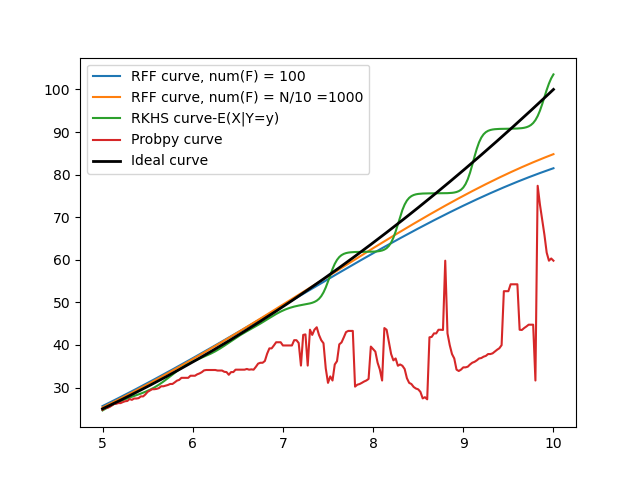
Implemented and tested the RFF method. Average Errors comparison between the three methods:
Probspace : 10.758674242461845
RKHS : 0.8640715047275058
RFF : 4.46337896
Here is a comparison graph between RKHS,RFF and ProbSpace methods:

Thursday & Friday:
I Compared the time taken for execution between the three methods. The RFF method also depends upon the number of features selected and the ‘sigma’ parameter. I conducted some tests to find the ideal sigma and feature size values.
The problem with feature sizes is that due to the random nature of vector selection, sometimes a feature size of size 10 produces more accurate results than a size of 1000. Theoretically, higher the feature size, the better the results should be. After fixing the random.seed() to generate pseudo random features, here are a couple of Feature Sizes vs accuracy comparison curves for different seed values:

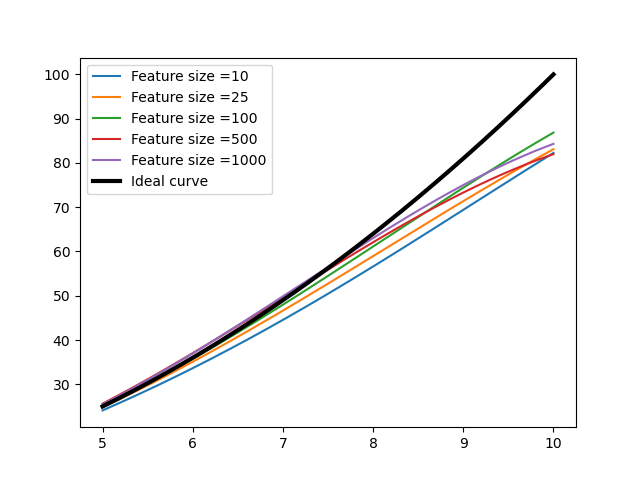
As seen, the results are inconclusive, however I’ve found that when the feature size ranges from N/10 to N/100 , the accuracy is most consistent. Similarly here is a Sigma values vs accuracy comparison curve with constant feature sizes:



Comments
Post a Comment