Week 2: Working with ProbSpace Module
This week I studied the existing Prob.py module which deals with the calculation of conditional probabilites, probability distributions and other functionalities. I also worked on understanding the paper dealing with Hilbert Space Embeddings of Conditional Distributions. Here is a day-wise summary of my progress throughout the week:
Monday:
Continued to experiment with rkhsTest2.py script. Implemented a sawtooth kernel and evaluation function. Discussed results of the same with Roger sir in the weekly meeting. As it turns out, it doesn’t matter what kernel function we use, given enough data points and time, we can derive an accurate probability distribution curve. Using the right kernel to fit the dataset helps us to arrive at the desired accuracy of the curve much faster and with far lesser data points.
Tuesday:
Studied the paper (Hilbert Space Embeddings of Conditional Distributions with Applications to Dynamical Systems ) to learn how to extract conditional probability distribution similar to how we obtained a regular PDF last week. Encountered difficulties with calculation of the beta(B) matrix which contains a list of weights(conditional probabilities) and is different for every testpoint.
Wednesday:
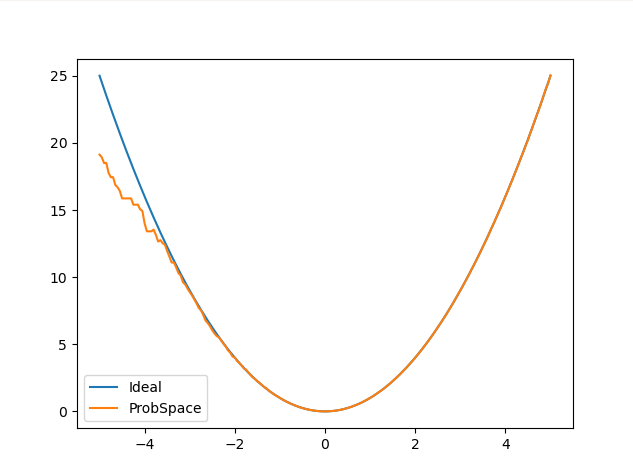
Worked on understanding the Prob.py module and after some testing around with the probTest.py, figured out how to use some of the major functions( conditional probability estimation E(Y| X=x) ). After comparing it with an ideal curve, it is very accurate at high density portions of the distribution but becomes inaccurate upon moving away from the mean. The goal is to eliminate this problem with the help of RKHS embedding.
Thursday:
Discussed results with Roger sir on the regular weekly meeting, had a discussion about how to proceed with the paper as it contained some difficult to understand math equations.
Friday:
Understood the paper better after a mail sent by Roger Sir explaining some of the notations and importance. Did some tests specifically to calculate µhat(X) and mean(X) = f(µhat(X)) which is required to calculate the Covariance matrix equivalent in the Hilbert Space. However it appears we have reached the limit for the usefulness of this paper.
Upcoming week plans:
Next week we will be focussing on a couple of easier to understand papers (Nonparametric Conditional Density Estimation and Fast Nonparametric Conditional Density Estimation)
Comments
Post a Comment